Better Search for Elm Packages
The search function in the Elm package index is relatively limited. Most importantly, documentation such as READMEs do not appear to be indexed, limiting the power of keyword search.
Similar to Haskell (perhaps most prominently, Hoogle), there is some ability to search by types. There has also been work done to associated metrics such as downloads to packages. I haven’t seen another project to build a deeper search index, though, so this experiment follows.
The steps to building the better search engine are:
- Scrape the relevant data (Python with Selenium)
- Build the index (vector space index with Python generating Elm data files)
- Implement the UI and query logic (Elm)
TLDR: try the app!
Scraping
Since the Elm package index is a single-page application that manipulates the DOM with JavaScript, simple HTTP GETs with tools such as requests don’t work. (More specifically, they just return the bare-bones HTML page that underlies every Elm application, without any of the actual application data that are rendered by the browser after processing the JavaScript.)
0Selenium is one tool to solve this problem. The basic instructions for installing and getting started with Python 3.x are all that’s required for this use case.
To open a page with the Chrome web driver and capture the browser-rendered HTML source:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get(url)
source = driver.page_source
driver.close()
Since the index generation will likely require several rounds of iteration, and network IO is expensive (in time, at least), the first step is to take a current snapshot of the package index.
This Python code follows each link from the Elm package index. If the GitHub source is missing, it skips. Otherwise, it downloads the README, About, and each of the exposed module documentation pages into local HTML files.
Scrape Results
THe scraping took a few hours and resulted in ~134MB of data on disk.
Some summary statistics (see Jupyter notebook):
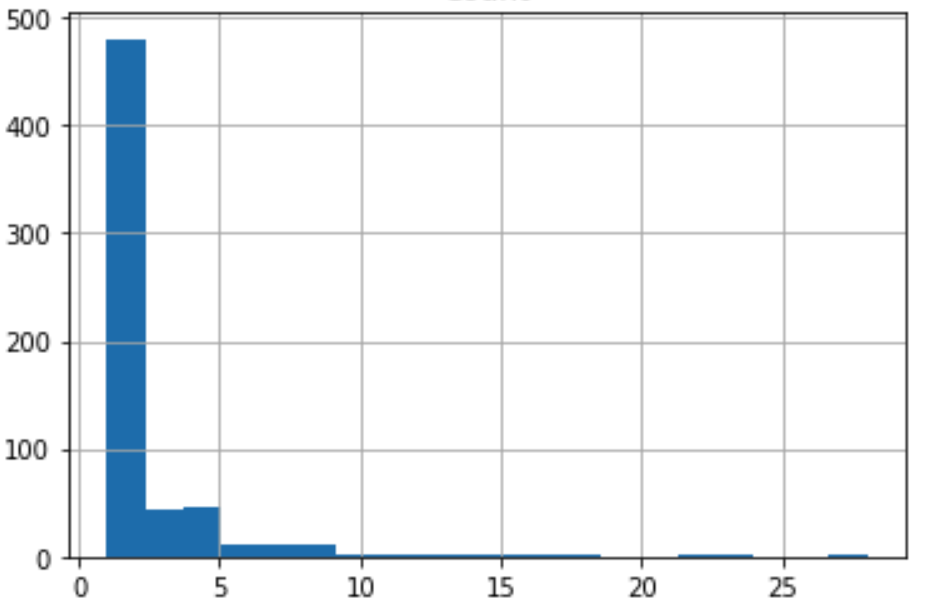
- There are 1457 packages, of which 48 (3.3%) are missing GitHub sources
- There are 623 distinct authors; the top 40 authors account for 32% of packages
- Most authors publish 1 or 2 packages (histogram of packages count per author below)
A few lessons lessons learned along the way:
- Even if the code is correct, there can be a variety of reasons for runtime crashes (e.g. computer falling asleep, unexpected interaction between the driver and other browser instances, etc). It’s good to save state aggressively, follow a reproducible (stable) path for getting collections of data, and log progress clearly – so that it’s easier to figure out where to resume from in case of a crash. Network IO is expensive for a single machine, so it’s good to avoid unnecessary repetition of work.
- In my experience, calling
driver.page_sourcewould sometimes yield incomplete pages. Whether a matter of timing or not, sleeping for a second after callingdriver.getmade such issues go away. (It looks like there is a better, more explicit way to solve this problem.)
Building the Index
Not having any prior knowledge of the space… the vector space model appears to provide a simple, classic algorithm for building a search index.
The term-frequency, document-inverse-frequency factor weighting can be tweaked for the domain of packages. Since package dependencies are listed (both in the source elm.json files as well as the About page), we can add a term that boosts more widely used packages (i.e. rewards high frequency of dependency).
After extracting and processing all the text from all the downloaded HTML files, the core index implementation looks like the below. gen_index generates an index for a single document (package) by scoring each tokenized and stemmed word in the document.
def gen_index(doc_term_map: Dict[PT.Word, Set[PT.IndexNum]],
dependency_map: Dict[PT.IndexNum, Count],
i: PT.IndexNum,
words: List[PT.Word]
) -> PT.PkgIndex:
"""Generate package index by scoring each word."""
word_freq: Dict[PT.Word, Count] = utils.count_freq(words)
total_docs = len(doc_term_map)
pkg_index: PT.PkgIndex = dict()
for word in word_freq:
doc_inverse_freq = get_doc_inverse_freq(total_docs,
len(doc_term_map[word]))
dependency_freq = get_dependency_freq(i, dependency_map)
pkg_index[word] = math.log(word_freq[word] *
doc_inverse_freq *
dependency_freq)
return pkg_index
def get_doc_inverse_freq(total_docs: int, term_doc_count: int) -> float:
"""Generate inverse doc frequency score with min of 1.0."""
return max(1.0, math.log(total_docs / term_doc_count))
def get_dependency_freq(i: PT.IndexNum,
dependency_map: Dict[PT.IndexNum, Count]
) -> float:
"""Generate dependency score as log of dependency count with min of 1.0.
Packages that are used by other packages score higher.
"""
return (1.0 if i not in dependency_map else
max(1.0, math.log(dependency_map[i])))
To Stem, or Not To Stem?
The input words to be indexed are pre-processed with tokenization and the PorterStemmer from NLTK. For plaintext, it makes sense. How about for code?
On the one hand, the code being included in the index consists mainly of function and type names – so it seems like they should perhaps be included literally. On the other hand, the query terms will be stemmed to match the stemmed plaintext, so unstemmed words in the index would decrease the search power. A cursory google search didn’t return insights on the topic. So, without much deeper consideration for whether it’s good or bad to stem code, all words are stemmed.
The Build Pipeline
Given data to index on disk, the build pipeline is as follows:
- first pass through all documents to build global data (scoring based on document-occurrences and package dependencies
- second pass through all documents to score each document, taking into account the global data
- pickle the index to facilitate testing
- perform validation on the generated index
- generate Elm modules that contian the package reference and index data
I typically prefer code gen over having the client make a resource request, as it is quick to generate Elm files with simple data structures, and it obviates the need for JSON decoders etc on the Elm client end.
The genarated files are not small, but not too large. The 16MB Elm module containing the index data is eventually gzip’ed as a single JavaScript file, yielding a ~1.8MB file (including the Elm application logic).
% du -h package_data/*.elm
16M package_data/PackageIndex.elm
356K package_data/PackageListing.elm
4.0K package_data/PackageTimestamp.elm
% du -h package_data/*.pkl
5.7M package_data/package_index.pkl
Querying the Index
Testing the generated index using the Python pickle, we see that search returns resonable results (note that the official Elm package index returns nothing for the query term “median”):
> validate_index.query(pkg_ref_dict, index_maps, 'median')
[(89, ('gampleman', 'elm-visualization'), 1.0),
(94, ('ianmackenzie', 'elm-geometry'), 1.0),
(96, ('ianmackenzie', 'elm-geometry-prerelease'), 1.0),
(113, ('jxxcarlson', 'elm-stat'), 1.0),
(704, ('f0i', 'statistics'), 1.0),
(725, ('folkertdev', 'elm-kmeans'), 1.0),
(767, ('gicentre', 'elm-vega'), 1.0),
(768, ('gicentre', 'elm-vegalite'), 1.0)]
In this case, there is a single query term, so all of the search results contain the query term exactly, yielding a score of 1.0.
The validation stage uses the same query function to implement some basic checks, like ensuring that querying by author and package name always returns the package as the first result.
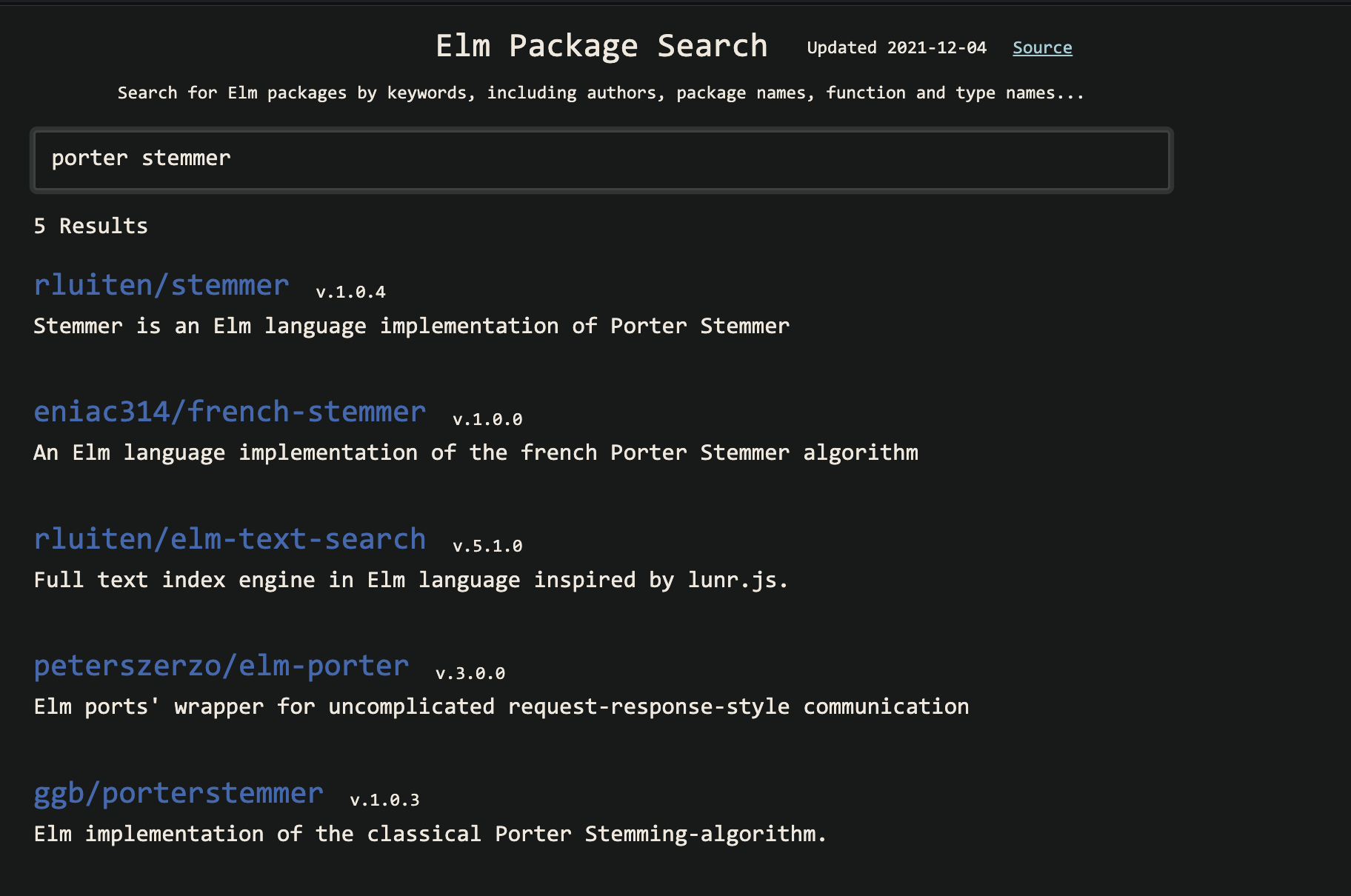
On the Elm client side, it is mainly setting up a UI to allow user input and display results. Fortunately, there is a PorterStemmer library in Elm as well – in fact, more than one, as shown by an index query:
As with the Python implementation, the Elm query function scores each document (package) in the index against the query terms and returns all matches in descending order of similarity score.
query : PkgRefMap -> List ( Int, PkgIndexMap ) -> List Word -> List QueryResult
query pkgRefDict indexMaps queryTokens =
let
scoredQuery =
Utils.countFreq queryTokens
|> List.map (Tuple.mapSecond toFloat)
in
List.map (cosineScore scoredQuery) indexMaps
|> List.map (toResult pkgRefDict)
|> List.filter (\( a, _, _ ) -> a > 0)
|> List.sortBy Utils.first
|> List.reverse
Wrapping Up
I added some diff’ing logic to the Python scraper, so it can incrementally retrieve version updates, as well as new packages that are added to the official Elm package index.
As a naive implementation of a keyword search engine… it seems to be reasonably useful – at least enough so for me to use personally in Elm projects.
At least two improvements come ot mind for future exploration:
- incorporate additional metrics for tie-breaking results of the same score, such as count of downloads from
npm(some prior discussion on this on Elm discourse) - identifying specific modules within packages, where relevant, and including them in query results (harder to do and may inflate the index daata quite a bit?)
Links